Toen ChatGPT in 2022 het daglicht zag, gaf het me een ongemakkelijk gevoel. Sindsdien kies ik ervoor om deze en andere LLMs niet te gebruiken. Ik schreef eerder over de invloed op werkgeluk, het energieverbruik, en risico’s voor de samenleving.
Nu de tool zo’n drie jaar oud is doe ik een poging om meer van mijn kriebels te duiden. Ik bespreek wat een LLM eigenlijk is, welk doel het dient en wat dat met ons doet.
Een LLM is een dataproduct
Hoe magisch een LLM ook lijkt, het is en blijft een dataproduct. Deze hebben een belangrijke grondstof: data. Voor een LLM zijn niet zomaar wat data nodig, er zijn zeer veel data nodig. Het zijn deze gegevens waaruit een algoritme verbanden kan ontrafelen. Deze ontrafeling vormt de basis van het dataproduct.
Laten we alle benodigde data in beeld brengen als 100 datapunten:

Het is goed om stil te staan wat data eigenlijk zijn. Als je met data werkt, komt de uitspraak ‘de data liegt niet’ wel eens voorbij. Achter deze uitspraak schuilt een geloof in de objectiviteit van data. Die objectiviteit is een illusie.
Elke vorm van data bestaat omdat een mens de keuze maakt om die data vast te leggen. Data die er niet zijn, zijn niet belangrijk genoeg gevonden door de groep mensen die daar een keuze over maakten.
Een simpel voorbeeld: als je wilt weten hoeveel personen zich identificeren met iets anders dan man of vrouw, dan moet je daar data over verzamelen. Als een groep die daar onderzoek naar doet die data niet verzamelt, zal deze kennis verborgen blijven. Daardoor bestaan de data niet. Deze verborgen data kent verschillende vormen: het kan totaal verborgen zijn (je geeft geen andere optie), de details kunnen verborgen blijven (alleen de optie ‘anders’ bestaat), of het kan een beperkt beeld geven (de gegevens opties zijn niet gedetailleerd genoeg).
Na het verzamelen van data vindt enige vorm van filtering plaats: welke data willen we wel meenemen en welke niet? Dit heeft vaak te maken met incomplete data, vervuilde data en soms ook ongewenste data. Deze filters worden wederom door mensen bepaald.
De ontwikkelaars van een dataproduct veranderen de totale data daarmee in de gewenste data en een deel van de datapunten valt zo weg:

Goed, je begrijpt waar ik heen wil: het ontwikkelen van een dataproduct is mensenwerk. Mensen bepalen welke data er zijn en welke data het product in gaan. Daarnaast maken ze ontwerpkeuzes om tot een bepaald doel te komen.
Het doel van het dataproduct
Een dataproduct bestaat omdat het een nut dient, of laat ik het anders zeggen: het zou een nut moeten dienen.
Het nut van een LLM als dataproduct ligt voor de hand: het maakt het makkelijk om grote hoeveelheden kennis te doorzoeken. Dit stelt mensen in staat om dingen sneller te doen en zelfs nieuwe dingen te doen die ze voorheen niet zelfstandig konden realiseren.
Vergeet echter niet dat achter veel van deze producten een tweede doel schuilgaat: winst. Veel van de producten zijn nu gratis of goedkoop. De producten zijn zo goedkoop om de kans te vergroten dat ze de grootste worden. Als ze dat eenmaal zijn en als enige speler overblijven, kunnen ze de regels van het spel aanpassen.
LLM als dataproduct
We kunnen het ontwikkelen van een dataproduct in een aantal stappen uiteenzetten:
- We leven in een wereld.
- Van sommige dingen in onze wereld legen we data vast (deze data geven een beperkt beeld van die wereld).
- Sommige van die data gebruiken we om een dataproduct te ontwikkelen (dit kan je zien als een beperkt beeld van het beperkte beeld).
- Het dataproduct behaalt in meer of mindere mate het doel waarvoor het bestaat.
In de realiteit is de ontwikkeling van een dataproduct niet zo rechtlijnig. Laten we dit proces daarom iets organischer in beeld brengen:
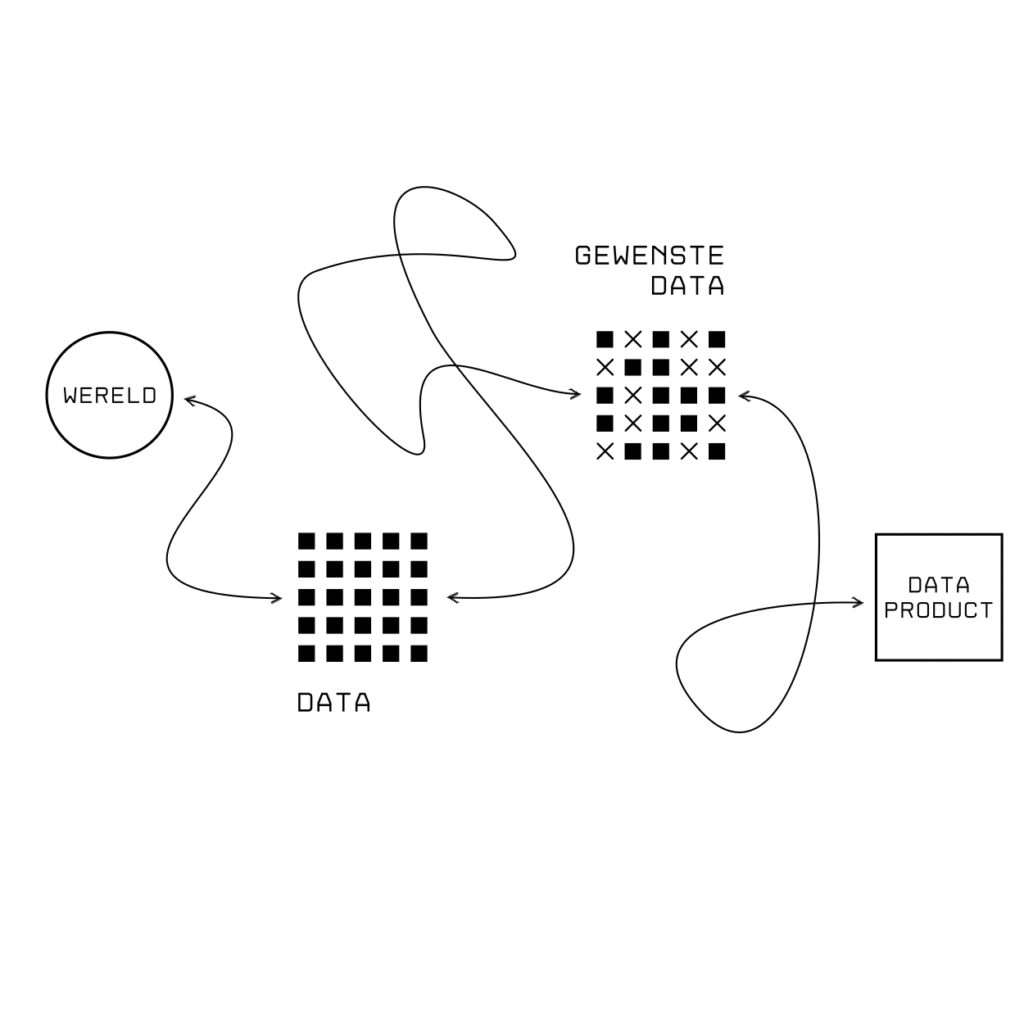
Het ontwikkelen van een dataproduct lijkt rechttoe rechtaan, maar is dat niet. Stappen hebben invloed op elkaar en keuzes achteraan in het proces vloeien terug naar het begin.
Het komen vragen bij mij op die resulteren in ongemakkelijke kriebels. Laten we ze bespreken, waarbij ik bij de data vooraan in het proces begin.
Waar komen al die data vandaan?
Zoals eerder gezegd, vraagt het ontwikkelen van een LLM om veel data. Erg veel data.
De beschikbaarheid van die data bepaalt wat zo’n model wel en niet kan. Tegenwoordig is er veel data in digitale vorm beschikbaar, maar niet alle informatie is in digitale vorm beschikbaar. Soms heeft het te maken met de taal: de Engelse taal heeft meer gedigitaliseerde informatie dan de Nederlandse taal. De taal is daarmee meer geschikt voor een LLM.
Soms heeft het te maken met de waarden binnen in cultuur: je zal online meer terugvinden over het bouwen van websites (iets wat direct gelinkt is aan de online wereld) dan over het onderhouden van een biodivers voedselbos. De beschikbaarheid van data heeft invloed op de mate waarin die data terug kunnen komen in het dataproduct. Er wordt soms gezegd dat LLMs bepaalde kennis en vaardigheden voor iedereen beschikbaar maken, maar daar komt dus enige nuance bij kijken: het maakt kennis en het gedachtegoed met voldoende gedigitaliseerde informatie toegankelijker. Met andere woorden: het versterkt culturen met een sterke digitale aanwezigheid. Wil je meegaan in het gebruik van een LLM, dan moet je daarvoor de cultuur die erdoor versterkt wordt omarmen.
Daar komt bij dat veel organisaties die nu een AI product ontwikkelen voor de korte weg kiezen: snel en makkelijk veel data binnenhalen. Zaken als eigendomsrecht worden bewust genegeerd om de snelheid erin te houden. Los daarvan bepaalt deze keuze (gebaseerd op snelheid en gemak) ook welk gedachtegoed het dataproduct ingaan.
Wie bepaalt wat gewenst is?
Als je die grote bak met data hebt, wil je deze in enige mate filteren. Zo’n filter baseer je op wat wel en niet gewenst is. Je komt zo van de totale data tot de gewenste data.
De reden hiervoor kan ik simpel uitleggen: als je een algoritme vraagt om een foto van een man te maken, wil je enige beperking aanbrengen in wat daaruit kan komen. Als je standaard alle foto’s van mannen op het internet ophaalt en al deze foto’s gebruikt voor je dataproduct, zit daar ongewenst materiaal bij. Denk bijvoorbeeld aan naakte mannen of beelden waarin zwaar lichamelijk letsel te zien is. Stel dat 50% van je data in de ongewenste groep valt en je daar niet van weet, dan is kans groot (zo’n 50%) dat een vraag als “maak een foto van een man” resulteert in een type beeld dat je liever niet ziet.
Het filteren van de data is dus belangrijk. Let wel: de keuze van wat gewenst is ligt (opnieuw) bij de maker van het product. Deze maker, die uit is op winst, bepaalt welke data én welke filters er relevant zijn voor een LLM. Het voorbeeld van de mannenfoto’s kan je makkelijk begrijpen. Maar soms is de lijn vager:
Hoe wil je als LLM-maker omgaan met kennis die kritiek geeft op LLMs?
Gebruik je een LLM?
Vergeet dit dan niet:
Een organisatie die uit is op winst, bepaalt welke realiteit een LLM je voorschotelt.
Wie doet het filterwerk?
Het aanbrengen van de splitsing in gewenste data en ongewenste data gebeurt door mensen. Sta hier even bij stil.
Stel dat het je baan is: je krijgt die collectie mannenfoto’s te zien waarvan de helft ongewenst is. Dat kan in een meer of mindere mate zo zijn, maar jij geeft er het label aan: dit is gewenst, dit is ongewenst. Dat is je baan.
De makers van de dataproducten weten dat dit geen leuk werk is. Daarom besteden ze het uit aan lage lonen landen waar groepen mensen dag in dag uit niets anders doen dan de meest ongewenste data van een stikker voorzien, zodat de maker van het dataproduct geen ongewenste data in het model stopt.
Deze arbeid is voor de eindgebruiker van een dataproduct niet zichtbaar, maar vindt wel plaats.
Welke vaardigheid versterkt AI?
In 1964 kwam het boek Understanding Media uit van Marshall McLuhan. Dit boek gaat over de effecten van media op onze samenleving. McLuhan stelt het volgende:
Elk medium is een verlenging van een menselijke vaardigheid.
Een simpel voorbeeld: de hamer maakt het makkelijker om een spijker in een plank te slaan. De hamer maakt ons daarmee minder afhankelijk van onze spierkracht en daardoor neemt die, als we de hamer gebruiken, af.
Als we dit doortrekken naar AI dan komt er een interessante vraag op:
Welke vaardigheid van de mens verlengt AI?
Voor mij raakt zo’n product mijn vindingrijkheid en creativiteit. De exacte impact is me niet duidelijk, maar schrikt me genoeg af om het niet te gebruiken.
Mijn gevoel is uit te leggen met het maken van een puzzel. Zonder GenAI, los ik een puzzel zo op:
- Ik bekijk de missende onderdelen.
- Ik zoek nieuwe kennis op.
- Ik speel met de nieuwe kennis om tot een oplossing te komen.
Met GenAI, lijkt het oplossen meer hierop:
- Ik geef mijn puzzel aan een LLM.
- Ik vraag: “los dit voor mij op”.
- Ik ga verder met de oplossing van de machine.
Het resultaat is functioneel gezien hetzelfde. De mate waarin ik de waarom van een oplossing begrijp voelt anders.
Waar ligt de controle op wat ik met mijn AI kan?
Daar komt nog een ander belangrijk aspect bij. Mijn eerste leidinggevende vertelde me twaalf jaar terug dit:
Bouw je huis niet op geleende grond.
Hij doelde destijds op Facebook. In de beginjaren maakten bedrijven gretig gebruik van het platform. Je kon er makkelijk veel potentiële klanten op bereiken. Later veranderde Facebook het speelveld: alleen door te adverteren (lees: geld te geven) kon je klanten blijven bereiken.
Met LLMs zal iets soortgelijks gebeuren: een van de spelers zal ‘de slag om AI’ winnen en vervolgens het speelveld naar hun hand zetten (lees: meer winst maken). Dit kan betekenen dat je meer moet gaan betalen om dezelfde output te behouden. Dit kan ook betekenen dat straks niet de beste inhoudelijke match op je vraag krijgt, maar een advertentiepartner voorrang krijgt in een antwoord van je AI (mogelijk is dit t.z.t. voor een kleine meerprijs uit te zetten).
Ons brein
Als een zin als aannemelijk klinkt, zijn wij mensen geneigd die over te nemen. Het vraagt enige mate van voorkennis om te detecteren dat een zin niet waar is.
Een mooi voorbeeld: in de begin periode maakte ChatGPT gebruik van oudere data. Als je bijvoorbeeld iets vroeg over de voetballer Lionel Messi, had het in antwoorden de huidige club soms fout. Dit is iets wat je snel ziet als voetbalfanaat, maar als leek merk je dat niet 1-2-3 op.
Minder onschuldig: tijdens de recente verkiezingen gebeurde iets soortgelijks: ChatGPT gebruikte oude partijprogramma’s als je vraagt om advies. Je moet al die partijprogramma’s goed kennen om dit als leek te detecteren.
Om onjuistheden te voorkomen zou je elke antwoord van een LLM handmatig kunnen nalopen. Maar daarmee gaat de efficiëntiewinst al snel verloren.
De kriebels
Met deze kennis op zak, komen we tot wat AI voor mij de kriebels geeft:
De makers van een LLM-product zijn uit op winst. De makers bepalen welk gedachtegoed het product ingaan en bepalen welk deel daarvan wel en niet gewenst is. Met deze keuzes proberen ze gebruikers voor zich te winnen én het liefst zoveel mogelijk via het dataproduct te laten doen (lees: tijd erop doorbrengen). Als ze dat als beste lukt, worden ze de enige speler in de markt. Als ze dat zijn, kunnen ze het product aanpassen om de winst te verhogen.
Begrijp me niet verkeerd: AI heeft waardevolle toepassingen en voor de kriebels die ik beschrijf zijn oplossingen. Het lijkt er alleen niet op dat de grote (Gen)AI spelers van dit moment daar actief op inzetten, of op z’n minst investeren in de bewustwording bij gebruikers.
Een metafoor
De afgelopen drie jaar ben ik GenAI gaan vergelijken met pesticide. Mijn voorbeeld leunt op de kennis uit het boek Difussion of Innovations (5th edition) van Everett M. Rogers. Dit boek bevat 50 jaar aan kennis over het doorvoeren van vernieuwingen in de sameleving. Zo’n lange periode geeft ruimte voor reflectie.
In zijn boek haalt Rogers pesticide aan. Aan het begin van zijn loopbaan vond hij boeren die het niet wilde gebruiker achterlopen, ookwel laggards genoemd. Tientallen jaren later werden de gevolgen van pesticide duidelijk: het put de grond uit, vervuilt de leefomgeving en er zijn gezondheidsrisico’s. Op korte termijn levert het wel degelijk meer op, maar op de lange termijn raakt de grond onbruikbaar. De achterlopende boer had wellicht een vooruitziende blik.
Ik kijk nu op eenzelfde manier naar GenAI: op korte termijn levert het meer op, maar op lange termijn put het iets uit. Wat dat iets is, weet ik niet precies, maar het is reden genoeg om nog even een biologisch brein te onderhouden.
Nieuwsgierig?
In 1966 lanceerde Joseph Weizenbaum de chatbot ELIZA. Toen hij dat deed, schrok hij van de mate waarin gebruikers menselijke eigenschappen op de chatbot projecteerden. Ze deden dit terwijl ze wisten dat het om een computerprogramma ging.
Zijn reactie hierop werd het boek: Computing Power and Human Reason. Dit boek gaat in op een belangrijke vraag:
We moeten niet nadenken over wat een computer kan doen, maar wat we een computer willen laten doen.
In een wereld die steeds sneller gaat en vol lijkt in te zetten op technologie als oplossing voor alles, vraagt dit om vertraging en de ruimte om nee te zeggen.
Ik schreef eerder artikelen over LLMs. Je vindt het overzicht hier.